In the last chapter, we covered how to enhance our endpoints and data models with helper methods. Now that we have a working library, it’s time to introduce the concept of “paging” our endpoints and how this helps your code perform better.
What do we mean by “paging”? Simply that we can retrieve a set of results in a limited amount; a “page” at a time.
Various APIs implement paging a little differently from the next. Most APIs with good documentation will actually have a full description of how their paging behaves. TheCatApi does as well.
If we visit this page https://docs.thecatapi.com/pagination we can see how it works.
It turns out that Paging, uses the parameter limit as well as page and order. The documentation page even has a Javascript implementation that you can fiddle with in the webpage itself. But to get a better handle on how it behaves, we’re going to open up our old friend Postman. If you’d like a refresher on Postman, visit chapter 1.
Let’s take the sample link in the documentation and drop it into Postman:
https://api.thecatapi.com/v1/images/search?limit=5&page=1&order=Desc
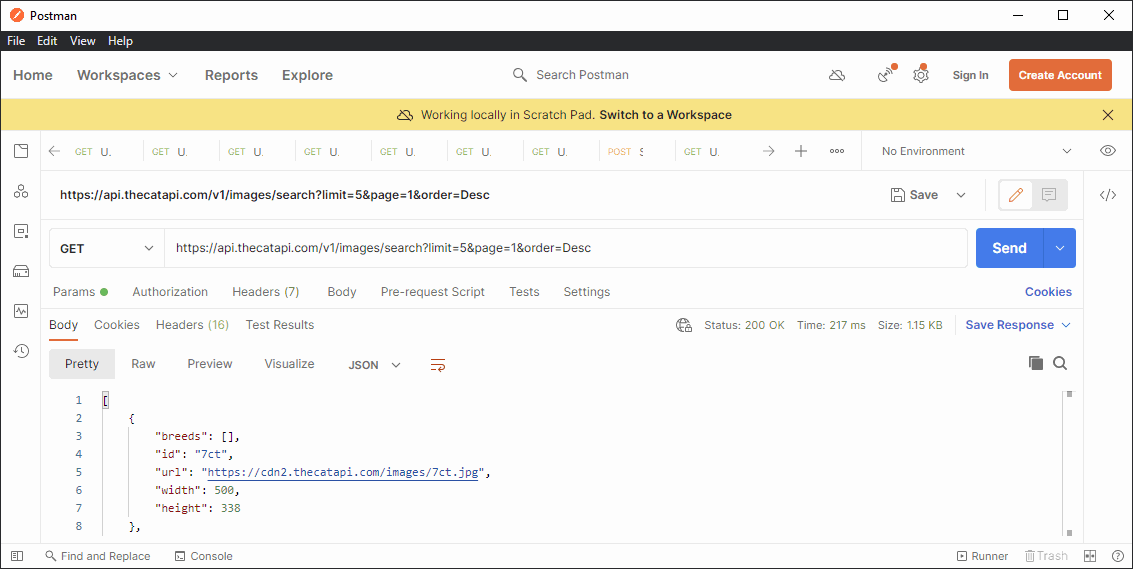
When we click SEND, we get back 5 kitties. And if you look closely, you can see that it took ~200ms. How many kitties can we get?
Let’s try 50! Sure enough, we get 50 kitties in ~5000ms.
What about 101 kitties? Nope, the endpoint only yields 1 kitty. It must have an internal limiter not mentioned in the documentation. And it takes ~350ms. Just to get 1 kitty.
Can we get away with 100? Yes, 100 kitties is a valid request. And it takes ~13000ms to fetch that many.
In the past few GETs, we’ve learned that:
- max kitties per request is 100
- min response time (overhead) is around 200ms
- max response time for 100 kitties is around 13000ms
So how many kitties should we get at a time? Let’s look at this chart.
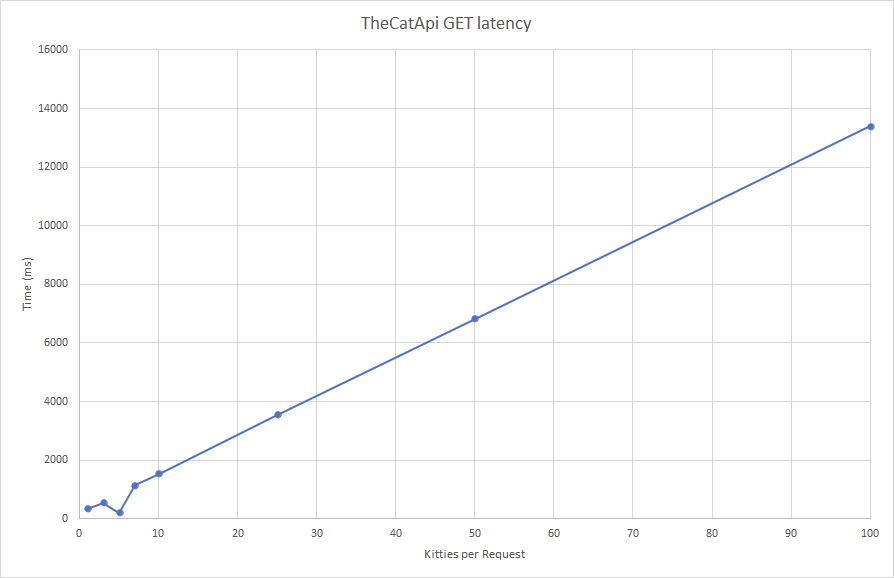
- We can see that the response time for getting 1 to 100 kitty records generally scales linearly.
- Yet there is a sweet spot at 5 kitties per request: 200ms
Let’s go with 5 kitties as our default paging amount.
Next, let’s explore the PAGE parameter and start at 1. If we click SEND, we get 5 kitties. If we click SEND again, we get 5 different kitties.
Well, that’s weird.
According to the documentation, we’re supposed to get the same kitties per page number. Well, it turns out that the documentation failed to mention that we need an API Key. Fortunately, you can get a basic one for free here: https://thecatapi.com/signup
Once you have your API key, drop it into Postman in the Header tab as x-api-key. Click SEND again, and you’ll get the same page of kitties over and over again until you change the PAGE number.
If we take a quick look at the Headers in the results, we see the pagination-count field and (at the time of this writing) it is over 21000 pages! At 5 kitties per page, that’s over 105,000 kitties!
Now that we have a handle on how the REST API doles out pages of kitties, let’s implement our own “paging” mechanism in Python.
Our new “get_kitties_paged” method will have 1 parameter, max_int, and a return type of Iterator[ImageShort]
The method has 3 steps:
- Setup: variables and parameters to pass to the API (“limit”, “order”, and which “page” we’re on)
- A
whileloop calling a new page worth of kitties until we’ve run out of pages or reached our max_amt - A
forloop that willyield1 kitty at a time
Here’s the method:
def get_kitties_paged(self, max_amt: int = 100) -> Iterator[ImageShort]:
# Init variables
amt_yielded = 0
curr_page = last_page = 1
endpoint = '/images/search'
ep_params = {'limit': self._page_size, 'order': 'Desc'}
# Keep fetching pages of kitties until the last page
while curr_page <= last_page:
ep_params['page'] = curr_page
result = self._rest_adapter.get(endpoint=endpoint, ep_params=ep_params)
# Increment curr_page by 1 and update the last_page based on header info returned
last_page = int(result.headers.get('pagination-count', 1))
curr_page = int(result.headers.get('pagination-page')) + 1
# Yield 1 kitty from the page; break/end loop if beyond max_amt
for datum in result.data:
yield ImageShort(**datum)
amt_yielded += 1
if amt_yielded >= max_amt:
last_page = 0
breakLet’s go over this line by line:
First 4 lines are about setting variables, params, endpoints, etc.
The while loop keeps going until we run out of pages. During this loop we:
- Set the current page and fetch a page full of kitties (limited to 5 by default)
Next we increment the current page count
And update the last page count (if the server informs that it has recently changed) - Then we “yield” 1 kitty at a time until we yield all 5 (or X amount) of the kitties in the page.
- Then we run out of kitties in our page, we return to the top of the while loop
- And get another page of kitties and repeat.
- When the amt_yielded exceeds the max_amt, we break from this method entirely.
Now, if you’re unfamiliar with the yield keyword, think of it like the return keyword. But instead of returning the entire page of kitties, we’re only returning 1 kitty and the method holds its state here in the loop. This effectively makes this get_kitties_paged() method behave like a List (well, if we’re being technical: an Iterator. Which is what it is when you use the yield keyword.)
Before we wrap up this chapter, let’s make this method more generic so that we can use it with any endpoint and any data model:
def _page(self, endpoint: str, model: Callable[..., Model], max_amt: int = 100) -> Iterator[Model]:
amt_yielded = 0
curr_page = last_page = 1
ep_params = {'limit': self._page_size, 'order': 'Desc'}
while curr_page <= last_page:
ep_params['page'] = curr_page
result = self._rest_adapter.get(endpoint=endpoint, ep_params=ep_params)
last_page = int(result.headers.get('pagination-count', 1))
curr_page = int(result.headers.get('pagination-page')) + 1
for datum in result.data:
yield model(**datum)
amt_yielded += 1
if amt_yielded >= max_amt:
last_page = 0
break
def get_kitties_paged(self, max_amt: int = 100) -> Iterator[ImageShort]:
return self._page(endpoint='/images/search', model=ImageShort, max_amt=max_amt)We took basically the same code, but added a couple more parameters and a generic Iterator as return. The only major change in the code is yield-ing the model(**datum)
What’s this Model that we’ve defined? Well, we defined it on the models.py file as:
Model = TypeVar('Model', covariant=True)It’s just a “generic” type hint to PyCharm. As you can see in the revised get_kitties_paged() method, the one line has a parameter that sets model=ImageShort. That’s the class that is later used in the yield statement.
This means that we can create other endpoint methods that take advantage of other data models.
Source code: https://github.com/PretzelLogix/py-cat-api/tree/13_paging_endpoints


2 replies on “Step 13: Paging the Endpoints”
[…] the next chapter, we’re going to cover Step 12: “Paging the Endpoints” and how this benefits your code […]
[…] Step 13: Page the endpoints […]