In the last chapter, we implemented a high-level endpoint called get_kitty(), but what if we wanted to get a clowder of kitties? We could call get_kitty() over and over again, but that incurs a lot of overhead and latency. It would be better if we just told the cat server that we wanted 10 kitties all at once instead.
Let’s start by looking at our first high-level endpoint:
def get_kitty(self) -> ImageShort:
result = self._rest_adapter.get(endpoint='/images/search')
kitty_img = ImageShort(**result.data[0])
return kitty_imgAnd let’s implement another high-level endpoint to serve us up a clowder of kitties.
def get_clowder_of_kitties(self, amt: int = 1) -> List[ImageShort]:
result = self._rest_adapter.get(endpoint=f'/images/search?limit={amt}')
kitty_img_list = [ImageShort(**datum) for datum in result.data]
return kitty_img_listLike the get_kitty() method, this is also a simple, but clever method.
Line 1 declares the method and hints to the developer environment that we will be getting an List of ImageShort objects back. It also gives the option of specifying the amount of kitties to get. The default being a List of 1 kitty.
Line 2 does the work of fetching the random kitty data. Here we’ve added the parameter limit={amt}
Line 3 is a list comprehension and takes all the results and puts them in a List of ImageShort using the same technique of using the double-star (**) operator to unpack the dictionary directly into the ImageShort type.
Line 4 returns the list of new ImageShort objects
Now that we have a way to get multiple kitties at once, we can actually refactor our first method to take advantage of this code.
def get_kitty(self) -> ImageShort:
return self.get_clowder_of_kitties(amt=1)[0]Whoa! What did we just do?
We took our WET (damp?) code and made it DRY again. The method that returns a list of kitties can also just return a single kitty now. The method get_kitty() is now a convenience method in the same way that get(), post(), and delete() are now convenience methods.
Ok, so now we have a couple ways to get kitties, but how do we download and view these kitties? So far, we’ve been getting objects of type ImageShort, but this class is perhaps misnamed as there is no actual “image” data contained within; only the URL where the image is located.
What we need to do to fetch the actual image data is to open a new connection using requests again and download the image from the website found in the URL field.
Initially, I had considered altering the _do() method to take an URL (and not just the one specified when instantiating the rest adapter), but this seemed like a classic case of a method trying to more than it should.
So what did I do?
Well, I did what any lazy programmer would do and copypasta’d the whole _do() method and renamed it download_image and put it in the rest_adapter.py file.
WHAT?!? Copypasta! WET Code! Bad programmer!
Yes, yes. It’s true. I copypasta’d the code, but significant changes were made. And here’s the result:
def fetch_data(self, url: str) -> bytes:
# GET URL; catching, logging, and re-raising any exceptions
http_method = 'GET'
try:
log_line = f"method={http_method}, url={url}"
self._logger.debug(msg=log_line)
response = requests.request(method=http_method, url=url, verify=self._ssl_verify)
except requests.exceptions.RequestException as e:
self._logger.error(msg=(str(e)))
raise TheCatApiException(str(e)) from e
# If status_code in 200-299 range, return byte stream, otherwise raise exception
is_success = 299 >= response.status_code >= 200
log_line = f"success={is_success}, status_code={response.status_code}, message={response.reason}"
self._logger.debug(msg=log_line)
if not is_success:
raise TheCatApiException(response.reason)
return response.contentAnd here’s the original _do() method for comparison:
def _do(self, http_method: str, endpoint: str, ep_params: Dict = None, data: Dict = None) -> Result:
"""
Private method for get(), post(), delete(), etc. methods
:param http_method: GET, POST, DELETE, etc.
:param endpoint: URL Endpoint as a string
:param ep_params: Dictionary of Endpoint parameters (Optional)
:param data: Dictionary of data to pass to TheCatApi (Optional)
:return: a Result object
"""
full_url = self.url + endpoint
headers = {'x-api-key': self._api_key}
log_line_pre = f"method={http_method}, url={full_url}, params={ep_params}"
log_line_post = ', '.join((log_line_pre, "success={}, status_code={}, message={}"))
# Log HTTP params and perform an HTTP request, catching and re-raising any exceptions
try:
self._logger.debug(msg=log_line_pre)
response = requests.request(method=http_method, url=full_url, verify=self._ssl_verify,
headers=headers, params=ep_params, json=data)
except requests.exceptions.RequestException as e:
self._logger.error(msg=(str(e)))
raise TheCatApiException("Request failed") from e
# Deserialize JSON output to Python object, or return failed Result on exception
try:
data_out = response.json()
except (ValueError, JSONDecodeError) as e:
self._logger.error(msg=log_line_post.format(False, None, e))
raise TheCatApiException("Bad JSON in response") from e
# If status_code in 200-299 range, return success Result with data, otherwise raise exception
is_success = 299 >= response.status_code >= 200 # 200 to 299 is OK
log_line = log_line_post.format(is_success, response.status_code, response.reason)
if is_success:
self._logger.debug(msg=log_line)
return Result(response.status_code, message=response.reason, data=data_out)
self._logger.error(msg=log_line)
raise TheCatApiException(f"{response.status_code}: {response.reason}")What’s the difference between the two? Well, the download_image() method doesn’t need to de-serialize any JSON, so that middle chunk gets cut out. It also returns a completely different object. An object made of bytes, rather than a Result. It also takes any old URL as input.
Could we make changes to merge both methods together? Probably, but at this point we have to ask ourselves if the extra effort is worth it. And what are the consequences? At this point, it’s probably fine. Both methods are fairly small and there don’t seem to be any real consequences by having 2 separate code paths for data connections, so let’s go forward with this for now. If we need to change it, we’ll refactor it later.
The next step is to go back to TheCatApi and to add a new method to take advantage of this new fetch_data() method. We’ll call it fetch_image_data and it will just be a 1-liner:
def fetch_image_data(self, image: ImageShort):
image.data = self._rest_adapter.fetch_data(url=image.url)This method takes an ImageShort object, fetches the data from the image URL, and then attaches the data to the image.
“But wait…”, you say. “ImageShort doesn’t have a data member variable.”
And this is true. So we change the __init__() method of ImageShort by adding data: bytes = bytes()
class ImageShort:
def __init__(self, id: int, url: str, categories: List[Category] = None, breeds: List[Breed] = None,
data: bytes = bytes(), **kwargs):This creates a new init parameter of type bytes which defaults to bytes() (which is an empty bytes object.)
And then we add the following line in the __init__ code:
self.data = dataOk, this is great and all, but we still don’t have a way to “save” the image data anywhere. We could write another method in TheCatApi, but let’s make this new method a member of ImageShort:
def save_to(self, path: str = './', file_name: str = ''):
if not self.data:
raise TheCatApiException("No data to save")
try:
save_file_name = file_name if file_name else self.url.split('/')[-1]
save_path = os.path.join(path, save_file_name)
os.makedirs(os.path.dirname(save_path), exist_ok=True)
with open(save_path, "wb") as f:
f.write(self.data)
except Exception as e:
raise TheCatApiException(str(e)) from eStart with the method and we pass in two optional params: path and file_name.
Path defaults to './' and file_name is an empty string.
Then we check to make sure that there is actual data to write, if not, we raise an exception.
After that we “try” a bunch of things:
- Check if the
file_nameparam was populated, if not extract the file name by splitting the URL on slash (/) and taking the last item of the list using the[-1]reference. (eg. a URL might look likehttps://cdn-site.com/some/path/to/catfile1.jpg) - Join the path and the file name using
os.path.join - Using
os.makedirstake the dirname of the save path and try to create it (if it doesn’t already exist) - Open the file in Write Binary (“wb”) mode and write out the data to the file
And that’s it! Let’s try it out in the REPL!
from the_cat_api.thecat_api import TheCatApi
from the_cat_api.models import *
catapi = TheCatApi()
kitty = catapi.get_kitty()
catapi.fetch_image_data(kitty)
kitty.save_to()And it may seem weird that there’s no output on the Python console… And that’s because your kitty image has been saved to a file.
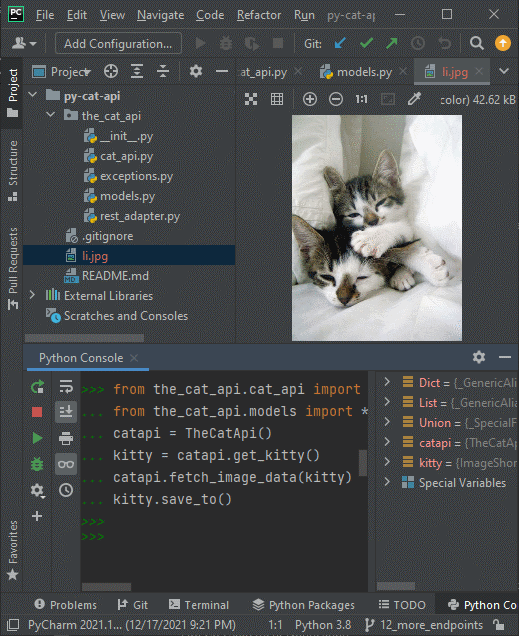
save_to() method, the kitty pic gets saved to the path your Python script executes from. In your IDE, you may notice that there is a new JPG file. If you open the file, PyCharm will display your kitty!
Ta-da! 🐱
At this point, we’re approaching the end of this 15 part tutorial, but we still have a few more topics to cover to wrap this up neatly.
For the next chapter, we’re going to cover Step 13: “Paging the Endpoints” and how this benefits your code base.
Source code: https://github.com/PretzelLogix/py-cat-api/tree/12_more_endpoints


4 replies on “Step 12: Create more Endpoints and Helper Methods”
[…] Chapter 12: More endpoints and helper methods […]
kitty_img_list = [ImageShort(datum) for datum in result.data]
needs to be:
kitty_img_list = [ImageShort(**datum) for datum in result.data]
Good catch. Fixed! (as a total aside, I now see how hard it would be to write/publish a programming book.)
[…] Step 12: Create more endpoints and helper methods […]